

2-Node Cluster в платформе vStack — это конфигурация из двух узлов, обеспечивающая непрерывную работу виртуальных машин и сервисов при отказе одного из серверов. Ключевой принцип: оба контроллера HA-пары должны иметь доступ к одним и тем же данным. Способ реализации этого доступа определяет тип кластера.
Зачем нужен 2‑node кластер
Классический отказоустойчивый кластер обычно ассоциируется с 3+ узлами и внешним хранилищем. Но в реальных проектах часто встречаются другие ограничения:
— ограниченный бюджет или ресурсы;
— небольшая площадка (филиал, ЦОД «у клиента»);
— необходимость быстро развернуть отказоустойчивость для критичных сервисов без сложной инфраструктуры.
Здесь и появляется 2‑node кластер — решение, позволяющее получить высокую доступность приложений и данных всего на двух физических серверах. При выходе из строя одного узла второй автоматически принимает на себя обслуживание дисковых ресурсов. Время переключения минимально, а данные остаются целостными. На базе платформы vStack можно построить полноценный двухузловой высокодоступный кластер виртуализации.
Общая классификация
Все варианты 2-Node Cluster делятся на две категории:
| Категория | Принцип работы | Арбитр |
| Общее хранилище (Shared Storage) | Диски физически «видны» обоим контроллерам | Не требуется |
| Локальные диски (Local Storage) | Каждая нода имеет собственные диски, данные синхронно реплицируются | Требуется арбитр (mediator) |
На основе этих категорий в vStack реализованы три основных типа развертывания.
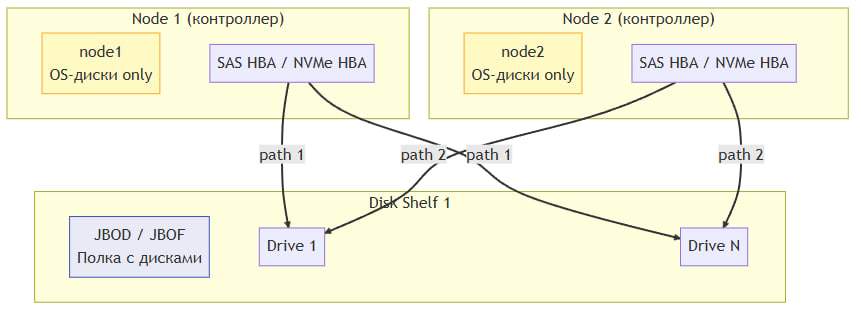
Тип 1 развертывания. Внешние дисковые полки (JBOD / JBDF)
Описание
Оба контроллера подключаются к внешним дисковым полкам (JBOD — Just a Bunch Of Disks, или JBOF — Just a Bunch of Flash) через кабельную инфраструктуру и HBA-адаптеры. Диски физически доступны каждому узлу одновременно. Разграничение доступа и предотвращение конфликтов записи обеспечивается программно (например, через SCSI Persistent Reservations).
Примеры оборудования
— Dell PowerEdge R760 / R660
— HPE ProLiant DL380 Gen10 Plus
Преимущества
— Масштабируемость хранилища — можно добавлять новые полки.
— Отсутствие репликации данных — экономия сетевых и вычислительных ресурсов.
— Мгновенное переключение (failover) — нет затрат времени на синхронизацию копий.
— Арбитр не требуется.
Ограничения
— Более высокая стоимость (полки + кабели + HBA-адаптеры).
— Физическая привязка нод к полкам.
— Для JBOF требуются специализированные dual-port NVMe-накопители.
— Необходима дополнительная кабельная инфраструктура.
Тип 2 развертывания. Двухнодовое шасси с общим бэкплейном
Описание
Обе ноды размещаются в одном шасси, которое имеет встроенный общий бэкплейн (backplane). Диски устанавливаются непосредственно в шасси и доступны обоим контроллерам через этот бэкплейн. Это специализированное оборудование, изначально спроектированное для HA-конфигураций.
Архитектура
Бэкплейн реализует двойной путь (dual-path) к каждому диску:
— path 1 — от контроллера 1
— path 2 — от контроллера 2
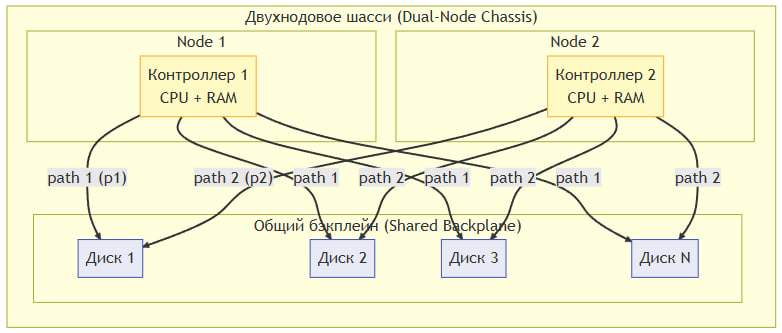
Оба контроллера видят все диски одновременно. Конфликты записи предотвращаются кластерным ПО vStack.
Примеры оборудования
— Supermicro BigTwin / TwinPro (SYS-2029BT-HNR) — 2 ноды в 2U, общий бэкплейн для NVMe/SAS
— Supermicro FatTwin (SYS-F629P3-RTB) — 4 ноды в 4U (используются 2 из 4 для HA-пары)
— Dell PowerEdge C6620 — многонодовое шасси с общим бэкплейном
— HPE ProLiant XL170r / XL190r — dual-node шасси Apollo серии
— Lenovo ThinkSystem SD530 — dual-node в 1U с общим бэкплейном
Преимущества
— Компактность — 2 ноды + диски в одном шасси.
— Простота кабельной разводки.
— Низкая латентность между нодами (внутренняя шина).
— Арбитр не требуется.
— Мгновенное переключение (failover).
Ограничения
— Специализированное (более дорогое) оборудование.
— Ограниченное количество дисковых слотов в шасси.
— Единая точка отказа — само шасси (питание, бэкплейн).
— Нет гео-распределения.
— Масштабирование емкости ограничено.
Тип 3 развертывания. Независимые ноды с локальными дисками
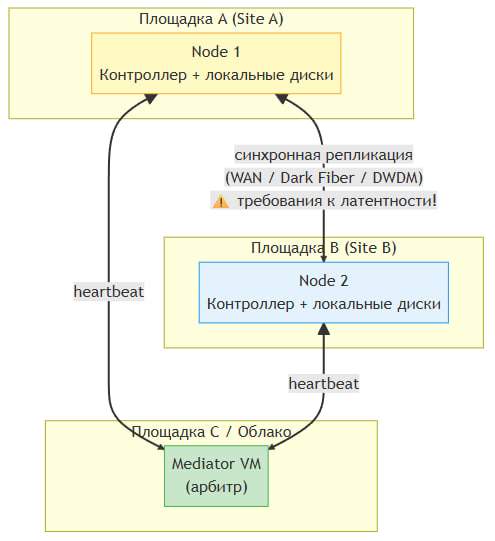
Каждая нода — полностью автономный сервер со своими локальными дисками. Диски одной ноды физически не доступны другой. Целостность данных обеспечивается за счет синхронной репликации между нодами на уровне кластерного ПО vStack.
Критически важный компонент — арбитр (mediator). Поскольку ноды не имеют общего хранилища, при потере связи между ними может возникнуть ситуация split-brain. Арбитр — это независимая виртуальная машина, которая выполняет роль «третьего голоса» в кворуме и предотвращает разделение кластера.
Тип 3а. Рядом стоящие ноды
Обе ноды расположены в одном или соседних серверных шкафах (rack), в одном ЦОДе. Синхронная репликация данных и heartbeat-каналы проходят по высокоскоростной сети.
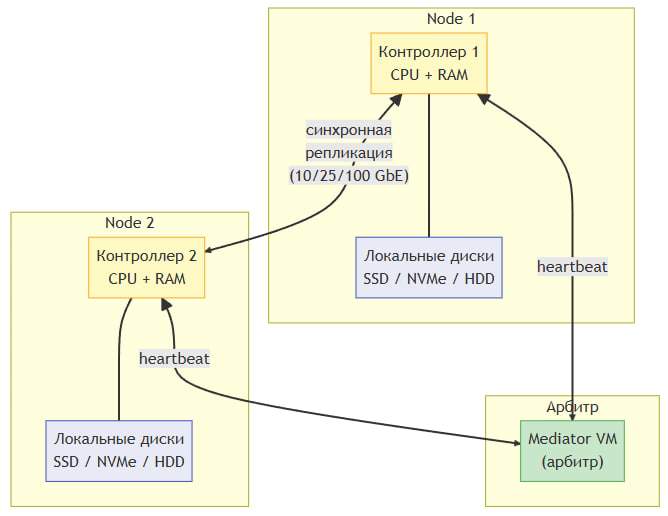
Тип 3б. Stretched Cluster (геораспределенный)
Ноды расположены в разных географических площадках (ЦОДах). Это обеспечивает защиту от катастрофических сбоев целой площадки (пожар, отключение питания, стихийное бедствие).
Требования к сети
| Параметр | Рядом стоящие ноды | Stretched Cluster |
| Репликация | 10/25/100 GbE (LAN) | WAN / Dark Fiber / DWDM |
| Латентность (RTT) | < 1 мс | < 5 мс (рекомендуется), < 10 мс (максимум) |
| Пропускная способность | ≥ 10 Gbps | Зависит от нагрузки записи |
| Heartbeat | Выделенная VLAN или отдельный интерфейс | Отдельный канал связи |
Роль арбитра (Mediator)
Арбитр — обязательный компонент для типа 3. Это легкая виртуальная машина, которая:
- Поддерживает heartbeat с обоими узлами кластера.
- Определяет доступность каждой ноды.
- Голосует в кворуме — при потере связи между нодами арбитр определяет, какая нода остается «живой» (primary), а какая должна быть изолирована (fenced).
- Предотвращает split-brain — гарантирует, что в любой момент только одна нода обслуживает данные.
Требования к арбитру:
— Минимальные вычислительные ресурсы: 1 vCPU, 512 MB RAM.
— Надежная сетевая связность с обоими узлами.
— Размещение на третьей независимой площадке (или хотя бы в независимом сетевом сегменте) — особенно критично для stretched cluster.
— Арбитр не должен находиться на тех же физических серверах, что и ноды кластера.
Сравнение типов 2-Node Cluster
| Характеристика | Тип 1: JBOD/JBOF | Тип 2: Общий бэкплейн | Тип 3а: Локальные диски | Тип 3б: Stretched Cluster |
| Общее хранилище | Да (внешние полки) | Да (бэкплейн шасси) | Нет | Нет |
| Арбитр | Не нужен | Не нужен | Нужен | Нужен |
| Репликация данных | Нет | Нет | Синхронная | Синхронная |
| Гео-распределение | Нет | Нет | Нет | Да |
| Время failover | Мгновенное | Мгновенное | Секунды | Секунды |
| Стоимость | Высокая (полки + dual-port) | Средняя-Высокая (спецшасси) | Низкая (стандартное оборудование) | Средняя (каналы связи) |
| Масштабируемость емкости | Высокая (добавление полок) | Ограниченная (слоты шасси) | Ограниченная (слоты серверов) | Ограниченная (слоты серверов) |
| Оборудование | Специализированное (полки) | Специализированное (шасси) | Стандартное | Стандартное |
| Сложность развертывания | Средняя | Низкая | Средняя | Высокая |
| Защита от отказа площадки | Нет | Нет | Нет | Да |
Рекомендации по выбору типа кластера
На основе документа можно сформулировать следующие рекомендации:
— Выбирайте Тип 1 (внешние дисковые полки), если вам требуется максимальная масштабируемость хранилища, вы готовы к более высоким затратам и можете обеспечить кабельную инфраструктуру. Подходит для средних и крупных ЦОД.
— Выбирайте Тип 2 (двухнодовое шасси), когда важны компактность, низкая латентность и простота монтажа, а масштабирование дисков не является критичным. Идеально для развертывания в ограниченном пространстве.
— Выбирайте Тип 3 (независимые ноды с репликацией), если вы хотите использовать стандартные серверы, важна гибкость, и особенно — если требуется защита от сбоя целой площадки (stretched cluster). Убедитесь, что у вас есть возможность разместить арбитр на третьей независимой инфраструктуре, а сетевая латентность между узлами не превышает 10 мс (и лучше 5 мс для stretched cluster).
Типовые сценарии использования 2‑node кластера vStack
1. Отказоустойчивая виртуализация в филиале
Два компактных сервера + локальное хранилище + кластер vStack → все сервисы филиала крутятся на виртуальных машинах с автоматическим перезапуском.
2. Минимальный HA‑кластер для критичных сервисов SMB
Небольшой бизнес, ограниченный бюджет, но нужны резервирование и гибкость. 2‑узловой кластер vStack дает:
3. Пограничные сервисы у заказчика
Кэширование, локальные БД, шлюзы, SCADA — все, что работает близко к источнику данных и не всегда может быть вынесено в облако. 2‑node кластер vStack обеспечивает локальную доступность и управляемость.

Заключение
vStack предлагает три основных типа 2-Node Cluster, каждый из которых имеет свои преимущества и ограничения. Выбор правильной архитектуры напрямую влияет на отказоустойчивость, стоимость и возможности масштабирования вашей инфраструктуры. Используйте shared storage (типы 1 и 2) для максимальной производительности и простоты failover, либо переходите на репликацию с арбитром (тип 3) для географической распределенности и работы на стандартном оборудовании.
Telegram
Facebook
Instagram
Twitter